계획했던 나만의 웹사이트 구축기 3부작의 마지막 편을 시작해보겠습니다.
지난 2편에서 AI 협업 도구와 i18n·MDX·조회수 시스템까지 블로그의 근간을 만들었습니다. 이번에는 이력서 페이지, Command Palette 검색, 그리고 배포까지 프로젝트의 마무리 여정을 공유합니다.
Resume 페이지 — 배너-아바타 헤더 레이아웃
Resume 페이지의 첫인상을 결정하는 배너-아바타 헤더는 구현은 단순하지만 시각적으로 임팩트 있는 레이아웃입니다.
UntitledUI 디자인을 레퍼런스로 삼은 것도 LinkedIn이나 Facebook 프로필과 유사한 느낌의 구도를 잡고 싶었습니다. 그렇게 이력서 페이지의 첫 화면에서 "이 사람이 누구인지"를 직관적으로 전달하면서 blue check badge 와 같은 걸로 SNS를 보듯 친숙한 느낌의 UI를 만들게 됩니다. 전체 폭 배너 이미지 위에 원형 아바타가 절반쯤 걸쳐지는 효과인데, CSS positioning 하나로 해결했습니다.
<section className="overflow-hidden rounded-2xl border bg-card">
{/* 배너 */}
<div className="relative h-48">
<Image src="/cover.png" alt="Cover" fill />
</div>
<div className="px-6 pb-6">
<div className="flex flex-col gap-3 sm:flex-row sm:items-end">
{/* 아바타 — -mt-12로 배너 하단에 걸치기 */}
<div className="relative z-10 -mt-12 h-24 w-24 shrink-0">
<Image
src="/avatar.png"
alt="Jerome Cheon"
width={96}
height={96}
className="h-full w-full rounded-full border-background object-cover"
/>
{/* Blue check mark */}
<span className="absolute right-0 bottom-0 flex h-6 w-6 items-center justify-center rounded-full bg-[#1D9BF0] text-white">
<BadgeCheck className="size-4" />
</span>
</div>
</div>
</div>
</section>-mt-12(음수 마진)와 border-background(배경색 테두리)의 조합이 핵심입니다. 아바타가 배너를 "뚫고 나오는" 느낌을 주면서, 다크/라이트 모드 전환에도 테두리 색상이 자연스럽게 따라옵니다.
About 섹션에는 긴 자기소개 문장을 300자 기준으로 자동 접는 Read more 토글 컴포넌트를 붙였습니다. max-height CSS 트랜지션으로 부드럽게 펼쳐지는 효과를 구현했습니다.
이력서 페이지에서 분량이 가장 큰 부분은 Project 섹션입니다. 이미 Notion에 정리해둔 포트폴리오 콘텐츠가 있었기 때문에, 이걸 다시 TypeScript 파일로 옮겨 적는 건 앱 개발과 무관한 별도 작업이 되어버립니다. 대신 API로 기존에 존재하는 데이터를 바로 가져오면 앱 개발 시간은 줄이면서 나중에 정적 데이터로 교체할 여지도 열어둘 수 있습니다.
Notion CMS 연동 — Project 섹션 데이터를 코드 밖으로
기존에 Notion에 프로젝트를 정리해둔 내용이 있었기에, 이 데이터를 우선 활용하여 서빙하는 것으로 결정했습니다.
이를 위해 Notion API를 발급받고 연동을 위한 @notionhq/client 라이브러리를 설치했습니다.
@notionhq/client를 직접 사용하는 간단한 레이어를 lib/notion/에 구성하는 과정에서 가장 신경 쓴 부분은 두 가지였습니다.
1. 지수 백오프 재시도: Notion API에는 rate limit이 존재하는데 이 rate limit이 비교적 낮아, 빌드 중 429 에러가 간헐적으로 발생. 이를 보완하기 위함.
// apps/web/lib/notion/projects.ts
async function withRetry<T>(fn: () => Promise<T>, maxRetries = 3): Promise<T> {
for (let attempt = 0; attempt < maxRetries; attempt++) {
try {
return await fn()
} catch (err) {
const isRateLimit =
err instanceof Error && err.message.includes('rate_limited')
if (isRateLimit && attempt < maxRetries - 1) {
await new Promise((resolve) =>
setTimeout(resolve, Math.pow(2, attempt) * 1000)
)
continue
}
throw err
}
}
throw new Error('Max retries exceeded')
}위와 같이 실패 시 1초 → 2초 → 4초 간격으로 재시도하는 지수 백오프를 적용했습니다. 이를 통해 빌드 중 API 호출이 간헐적으로 실패해도 빌드 전체가 중단되는 상황을 방지합니다.
2. React.cache()로 중복 호출 제거: 여러 컴포넌트에서 동일한 프로젝트 목록을 필요로 할 때, cache() 래핑 한 줄이 request 당 API 호출을 1회로 고정.
// apps/web/lib/notion/projects.ts
export const getProjects = cache(async (): Promise<Project[]> => {
try {
const notion = getNotionClient()
const dbId = process.env.NOTION_PORTFOLIO_DB_ID
if (!dbId) return []
const response = await withRetry(() =>
notion.dataSources.query({ data_source_id: dbId })
)
return response.results
.filter(isFullPageOrDataSource)
.filter(isFullPage)
.map((page) => ({
id: page.id,
name: extractTitle(page.properties, 'Name'),
description: extractRichText(page.properties, 'Description'),
tech: extractMultiSelect(page.properties, 'Tags'),
period: formatPeriod(extractDate(page.properties, 'Date')),
markdownContent: '',
}))
} catch (err) {
console.error('[notion] getProjects 오류:', err)
return []
}
})Notion API 장애가 발생하면 getProjects는 빈 배열을 반환하고, 개별 프로젝트 상세(getProjectById)에서는 lib/resume/data.ko.ts의 정적 데이터로 fallback됩니다.
Resume 페이지는 ISR revalidate: 1800(30분)으로 설정해 배포 없이도 Notion 변경 사항이 주기적으로 반영되게 하였습니다.
Command Palette 검색 — 정적 JSON 인덱스 전략
전역 검색을 구현하면서 "검색 서버를 따로 운영하지 않을 방법"을 먼저 고민했습니다. Algolia나 외부 검색 서비스를 붙이면 강력하지만, 지금 규모에서는 오버엔지니어링이 될 것 같았습니다. 어차피 콘텐츠는 MDX 파일로 관리되고 있으니, 빌드 시점에 인덱스 JSON을 만들어두고 CDN에서 서빙하면 되는 거 아닐까 하는 생각에서 정적 JSON 인덱스를 prebuild 하는 아이디어로 출발했습니다.
- 빌드 시점 인덱스 생성:
pnpm prebuild훅에 스크립트를 등록해next build실행 전에 자동으로 인덱스를 만들도록 했습니다.buildIndexForLocale()이 각 locale의 MDX 파일을 읽어 frontmatter를 파싱하고, 포스트와 섹션 네비게이션 항목을 통합한 JSON을public/에 저장합니다.
// apps/web/scripts/build-search-index.ts
function buildIndexForLocale(locale: Locale): SearchIndexItem[] {
const localeDir = path.join(CONTENT_DIR, locale)
const items: SearchIndexItem[] = []
if (fs.existsSync(localeDir)) {
const files = fs.readdirSync(localeDir).filter((f) => f.endsWith('.mdx'))
for (const file of files) {
const filePath = path.join(localeDir, file)
const { data } = matter(fs.readFileSync(filePath, 'utf-8'))
const slug = (data.slug as string) ?? file.replace(/\.mdx$/, '')
const category = data.category as string | undefined
// URL에 locale prefix 없이 저장 — CommandPalette의 useRouter가 현재 locale 자동 적용
const url =
category === 'tech' || category === 'life'
? `/${category}/${slug}`
: `/tech/${slug}`
items.push({
type: 'post',
slug,
title: (data.title as string) ?? slug,
description: data.description as string | undefined,
category,
tags: (data.tags as string[]) ?? [],
publishedAt: data.publishedAt as string | undefined,
url,
locale,
})
}
}
// 포스트 + 섹션 네비게이션 항목(Home, Tech, Life, Resume) 통합
return [...items, ...NAV_ITEMS[locale]]
}이렇게 만들어진 search-index.ko.json과 search-index.en.json은 public/에 위치해 CDN에서 직접 서빙됩니다.
별도 API 엔드포인트가 필요 없으니 서버 비용도 없고, 응답도 빠르죠.
- 런타임 동작: 사용자가
/키를 입력하거나Cmd/Ctrl+K를 누르면 Command Palette가 열리면서 인덱스 JSON을 한 번 fetch합니다. 이후 타이핑할 때마다 클라이언트 측 필터링이 즉시 이루어지고, 검색 결과를 클릭하면next-intl의useRouter를 통해 현재 locale을 유지한 채 해당 페이지로 이동합니다. 한국어로 보던 중 검색해서 클릭해도, 한국어 경로로 그대로 이동합니다. UI는shadcn/ui의Command컴포넌트(cmdk 기반)로 구현했습니다.
현재는 제목·태그·설명 등의 메타데이터 기준 단순 필터링이라 본문 전문 검색은 지원되지 않습니다. 추후 콘텐츠가 늘어나면 Fuse.js 기반 퍼지 검색으로 교체할까도 생각중에 있습니다.
SEO — Next.js Metadata API
App Router를 사용하면서 메타데이터 관리가 얼마나 단순해지는지 직접 확인한 부분입니다.
블로그를 만들면서 SEO는 생각보다 신경을 많이 쓰게 되는 부분이었는데, 다행히 generateMetadata로 페이지별 동적 메타데이터를 처리하는 방식이 내장돼 있어 별도 플러그인 없이도 충분히 해결할 수 있었습니다.
포스트 상세 페이지에서는 frontmatter의 제목·설명·태그를 그대로 OG 태그에 매핑합니다.
sitemap과 robots.txt는 Next.js의 규칙을 따르는 파일로 자동 생성됩니다.
app/sitemap.ts에서 모든 포스트 slug를 순회해 locale 변형(/ko/, /en/) URL을 포함한 sitemap을 내보내고, app/robots.ts는 Vercel 배포 URL을 sitemap 경로로 등록합니다.
// app/sitemap.ts (개념적 구조)
export default async function sitemap(): Promise<MetadataRoute.Sitemap> {
const posts = await getAllPosts()
const postEntries = LOCALES.flatMap((locale) =>
posts
.filter((p) => p.locale === locale)
.map((p) => ({
url: `${siteUrl}/${locale}/${p.category}/${p.slug}`,
lastModified: p.publishedAt,
}))
)
return [...staticPages, ...postEntries]
}Vercel 배포 — 모노레포와 환경변수
모노레포를 배포할 때 가장 흔히 막히는 지점이 Root Directory 설정입니다.
Turborepo 모노레포에서 Vercel 배포 시 Root Directory를 apps/web으로 지정하는 것이 핵심인데, 이 설정 하나로 Vercel이 올바른 빌드 대상을 인식하여 어렵지 않았습니다.
깃허브 레포지토리 연결 후 배포 시, 환경변수를 Vercel 프로젝트 설정에 등록하고, preview 배포는 제외하였습니다.
한편 Vercel 에서 제공하는 기능 중 하나인 Analytics도 활성화 하여 아래 두 줄로 연동 가능합니다.
// app/[locale]/layout.tsx
import { Analytics } from '@vercel/analytics/next'
export default function RootLayout({ children }) {
return (
<html>
<body>
{children}
<Analytics />
</body>
</html>
)
}Vercel 대시보드에서 페이지별 방문자 수와 경로 통계를 바로 확인할 수 있어, Supabase 조회수 데이터와 함께 콘텐츠 성과를 파악하는 데 유용합니다.
글을 맺으며
기획 이후 배포까지 약 8일이 걸쳐 개발을 완료했습니다.
순수 개발 시간만으로는 약 19시간 정도인데 하루 하루 나눠서 하다보니 처음 러프하게 잡았던 것보다 좀 더 걸렸네요...
참고로 이 프로젝트 전체에 소요된 Claude 사용량을 세션 리포트로 뽑아봤습니다 (2026-05-12 ~ 05-19, 8일 기준).
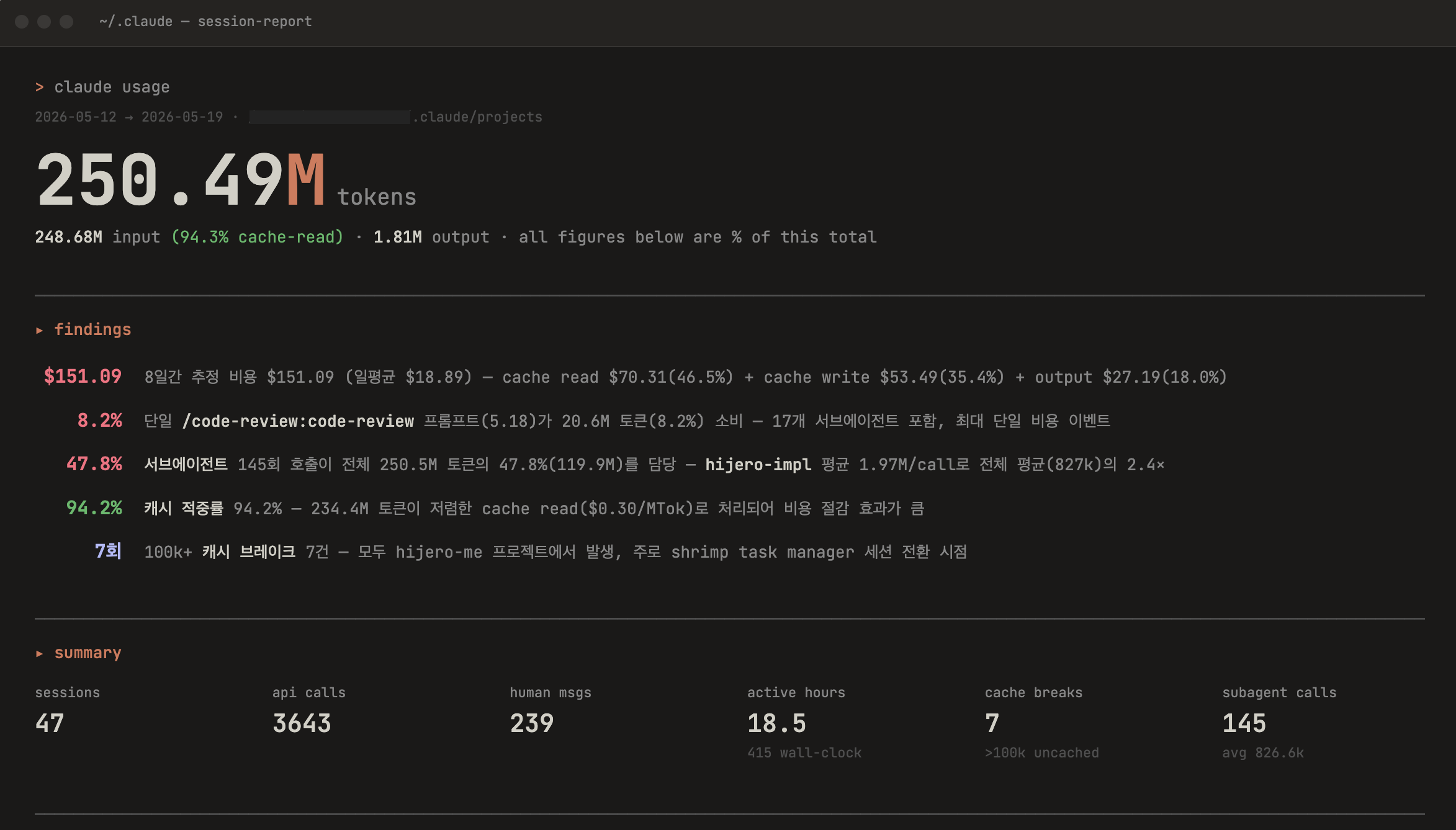
실제 활성 작업 시간은 18.5시간, 총 API 호출 3,643회, 사용한 토큰은 약 2억 5050만 개(입력 2억 4870만 + 출력 181만)였습니다. 추정 비용은 $151.09(claude-sonnet-4-6 기준)로 일평균 $18.89 수준이었습니다.
비용 구성을 보면 캐시 읽기 $70.31(46.5%) · 캐시 쓰기 $53.49(35.4%) · 출력 $27.19(18.0%) 순이었고, 주 소모원은 서브에이전트 145회 호출(전체 토큰의 47.8%)이었습니다. Shrimp Task Manager의 의존성 그래프와 태스크 컨텍스트가 크다 보니, 세션마다 이를 통째로 읽는 캐시 비용이 가장 큰 항목을 차지했습니다.
클로드에게 물어봤을 때 전반적으로 정상 범위라고 합니다.
캐시 적중률 94.2%는 건강한 수준이고, 서브에이전트 비중 47.8%는 Shrimp Task Manager 기반 자동화 워크플로우를 감안하면 예상 범위 내입니다. 일평균 $18.89는 기능 구현에 집중했던 기간임을 고려하면 합리적인 수치입니다.
한 가지, 리포트를 보면서 뒤늦게 깨닫게 된 게 있었습니다.
저는 컨텍스트가 80%에 육박할 때마다 /clear로 날려버리는 게 깔끔하다고 생각했는데, 그럴 때마다 새 세션이 생성되면서 CLAUDE.md 같은 대형 설정 파일이 다시 cache write된다는 부수효과가 있었습니다.
세션을 자꾸 새로 만들수록 캐시 쓰기 비용이 올라가는 구조였던 것이죠.
이번 기회에 알게 돼서 앞으로는 /compact를 더 적극적으로 활용해야겠다는 인사이트도 얻었네요.
이 프로젝트를 진행하며 PRD → 검증 → ROADMAP → Shrimp Task Manager로 이어지는 파이프라인 덕분에 "지금 뭘 만들어야 하는지"가 항상 명확했고, 그 컨텍스트 위에서 AI와 협업하니 흔들림 없이 전진할 수 있었습니다.
AI 협업 방식에서 특히 효과적이었던 것은 두 가지였습니다.
하나는 Claude Code의 output-style을 learning으로 설정한 것입니다. 단순히 코드를 받아 붙여넣는 게 아니라, 구현 선택에 대한 Insight와 배경을 함께 받으면서 코드베이스에 대한 이해를 쌓는 방식이었습니다.
다른 하나는 hijero-scaffold와 hijero-impl 두 서브에이전트를 별도로 정의한 것입니다. scaffold 에이전트는 뼈대만 만들고 TODO(human) 마커를 남기는 역할에 한정하고, 핵심 로직과 설계 판단은 직접 채워 넣었습니다. AI가 모든 것을 구현해 주는 게 아니라, 코드베이스에 대한 오너십을 유지하면서 협업하는 구조가 생산성과 학습 모두에 도움이 됐습니다.
이것으로 hijero.me 웹사이트의 기본 구축은 마무리되었습니다. 소스 코드는 GitHub 저장소에서 확인해 보실 수 있습니다.
이 다음으로는 사이드 프로젝트 전용 대시보드 개발, 커스텀 도메인 구매 및 연결, 성능 최적화 같은 보완 작업을 진행할 예정입니다. 이런 내용들은 앞으로도 별도 포스트로 하나씩 정리해 나가보겠습니다.
이 시리즈가 AI를 활용하여 개인 웹사이트를 구축하고자 하는 분들께 조금이나마 도움이 되었으면 좋겠습니다. 긴 글 읽어주셔서 감사합니다.