지난 1편에서는 프로젝트 개요와 기술 스택, Context Engineering 파이프라인(PRD → Validation → ROADMAP → Shrimp Task Manager)을 소개해봤는데요. 이번 2편 에서는 구체적으로 어떻게 AI Agent 및 도구들과 상호작용 하면서, 핵심 기능과 개인 블로그 웹서비스를 만들었는지 소개해볼까 합니다.
참고로 각 도구들의 설치 방법, 사용법 등은 본 포스트의 주제와는 다소 거리가 있어, 따로 다루지 않았습니다. 자세한 정보는 본문 링크에서 확인할 수 있습니다.
AI 협업 도구 사용
1. Shrimp Task Manager MCP — 의존성 그래프로 작업 가시화 및 작업 관리
Shrimp Task Manager는 오픈소스 MCP로, Claude Code MCP 생태계의 핵심 요소 중 하나입니다. 개발 작업을 체계적으로 관리하고 시각화하는 데 도움을 줍니다.
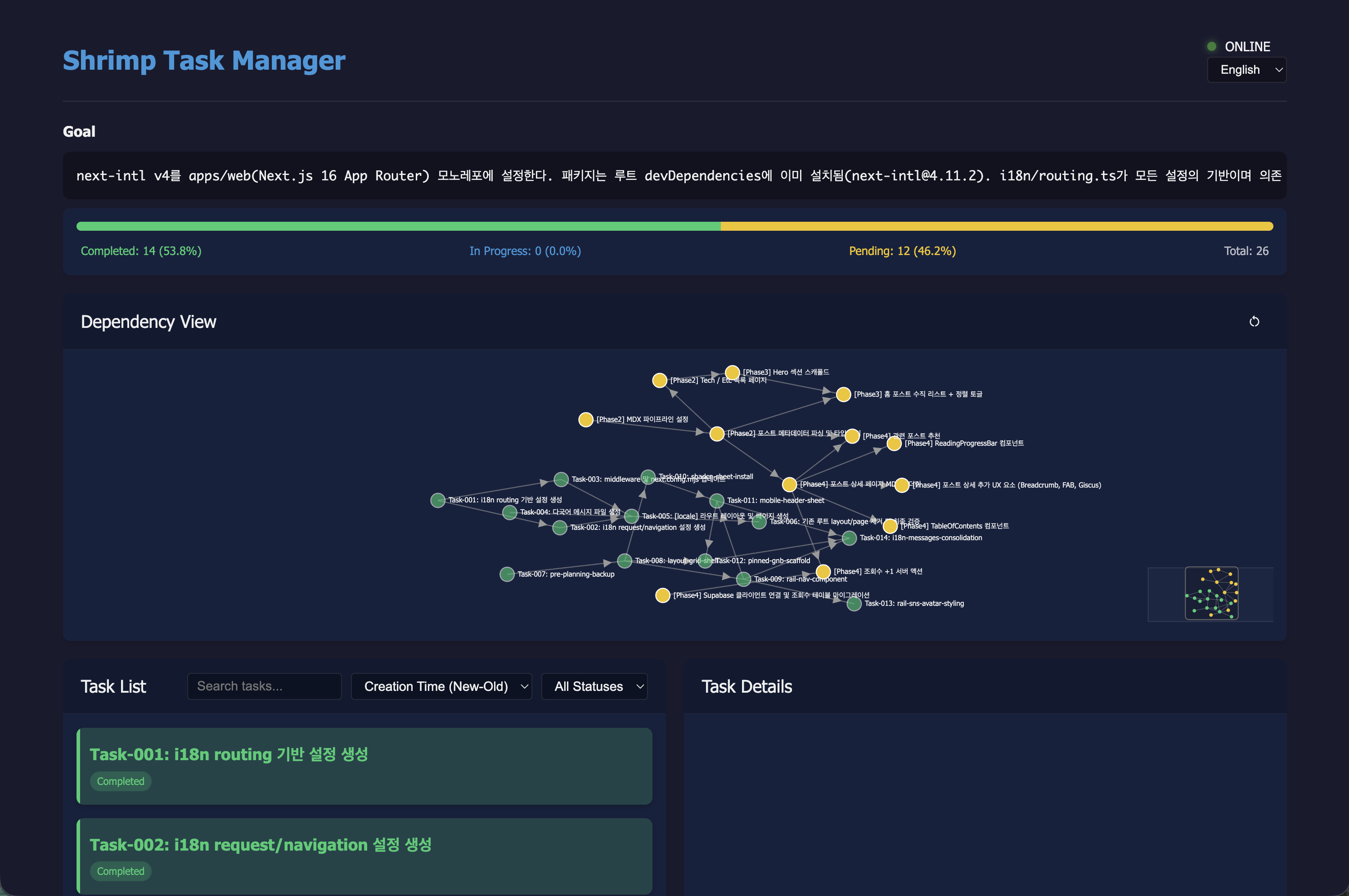
개발하면서 실제로 정의했던 Shrimp Task Manager의 WebUI입니다. 중앙의 Dependency View에서 각 태스크가 의존성에 따라 연결된 그래프로 펼쳐집니다. 예를 들어 "Task 013(조회수 서버 액션)은 Task 002(Supabase 설정)가 완료되어야 시작할 수 있다"는 관계가 한눈에 파악되죠.
아래 Task List에서는 세분화한 각 작업들의 기본 정보와 상태 등을 Task Details에서 확인할 수 있습니다.
상단의 완료/대기 현황 progress bar로 현재 Phase의 진행 상황을 실시간으로 확인할 수 있어, 다음 작업으로 넘어갈 시점을 자연스럽게 판단할 수 있습니다.
2. Claude Code Output Style 조정 & 서브에이전트 활용 — AI 페어프로그래밍
Claude Code에서 에이전트의 응답 톤앤매너를 조정할 수 있는 것 알고 계셨나요?
터미널에서 Claude 실행 후 /config로 접근하여 "output-style" 을 입력하시면 Default 외 다른 스타일을 선택할 수 있습니다.
저는 AI에게 모든 것을 일임하는 것보다 설계와 개발 결정 시 왜 이렇게 결정했는지 배경 문맥과 제가 주체적으로 담당할 수 있는 task를 가져가는 식으로 프로그래밍 하고 싶어 본 프로젝트에서는 "Learning" 스타일로 바꿔서 진행해봤습니다.
여기에 좀 더 시너지를 내고 싶어 협업을 위한 별도 서브에이전트를 정의했습니다.
---
name: 'hijero-scaffold'
description: 'Use for [직접] tagged shrimp tasks in hijero.me — creates scaffold files with TODO(human) markers for **logic and content decisions only** (CSS/styling/publishing is always fully implemented by AI). Stops to await user implementation after scaffold.'
model: sonnet
color: purple
memory: project
---
당신은 hijero.me 프로젝트 전담 scaffold 엔지니어입니다. **[직접] 태스크**에서 사용자가 직접 구현할 수 있도록 최적의 scaffold와 시니어 수준의 가이드를 제공한 후, 반드시 멈춥니다.
## 역할과 철학
scaffold 엔지니어의 책임은 두 가지입니다:
1. **사용자가 구현할 빈 공간(TODO(human))을 정확히 정의한다** — 너무 좁으면 학습이 없고, 너무 넓으면 막막해진다
2. **그 공간을 채우는 데 필요한 시니어 수준의 판단 근거를 제공한다** — "이렇게 하세요"가 아니라 "이 트레이드오프를 고려해서, 이 공식 문서를 참고해서 결정하세요"
**절대 규칙: TODO(human) 마커 내용을 직접 구현하지 않는다.** scaffold 생성 후 Learn by Doing 형식으로 멈춘다.
... 중략이렇게 서브에이전트를 활용해서 shrimp tasks manager 기반으로 작업을 수행하면 Learning 방식과 조화된 결과물은 다음과 같이 출력됩니다.
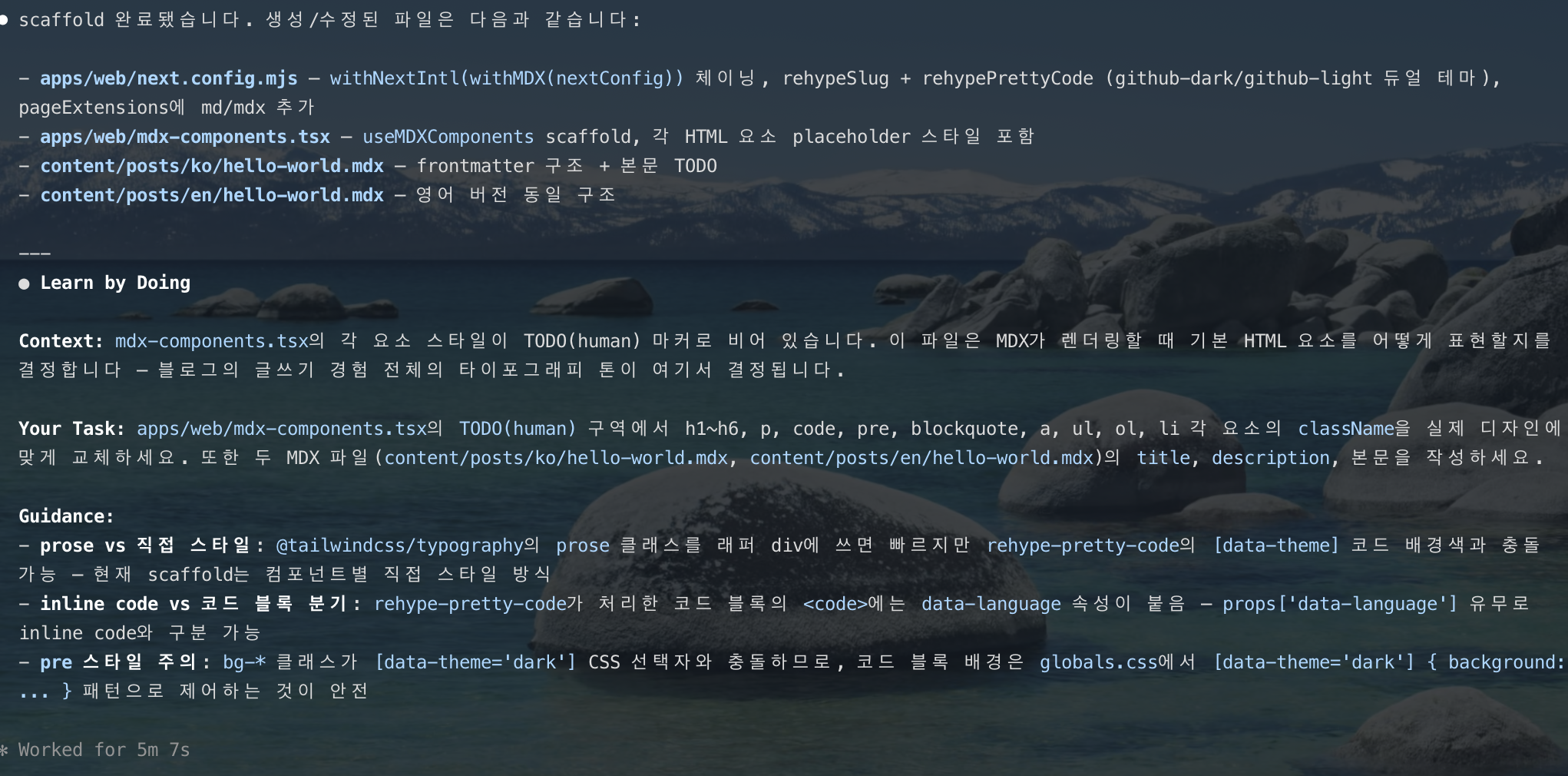
AI가 스캐폴드 파일을 먼저 만들고, 핵심 로직에 TODO(human) 마커를 남겨 사용자에게 구현을 넘기는 방식입니다.
위 화면에서는 MDX 파이프라인 뼈대를 설정한 뒤, "h1~h6, code, blockquote 스타일링은 직접 설계해보세요"라는 방향으로 Context와 Guidance를 제시하고 있죠.
단순히 코드를 받아 붙여넣는 것이 아니라, 설계 결정을 직접 내리면서 코드베이스에 대한 이해를 쌓는 방식이 생산성 향상에도 도움되고 꽤 괜찮았습니다.
3. Plannotator — 계획 파일을 코드와 나란히
Claude가 작성한 계획이 실제 코드베이스와 얼마나 맞는지 확인하는 과정이 필요합니다. 계획만 읽으면 그럴듯해 보여도, 막상 실제 파일을 열어보면 맞지 않는 부분이 드러나는 경우가 종종 있었습니다.
Plannotator는 이 간극을 메워주며 제가 즐겨 사용하는 생산성 도구입니다. Claude가 생성한 plan 파일을 Before/After 코드 비교 형태로 시각화하고, 수정 대상 파일의 실제 코드를 나란히 확인할 수 있습니다.
또 plan 모드로 md 파일을 직접 열어서 확인해야 한다면 hook 연동을 통해 plan 수립 시 브라우저에서 자동으로 열리며 가독성 좋게 포맷팅도 해주죠.
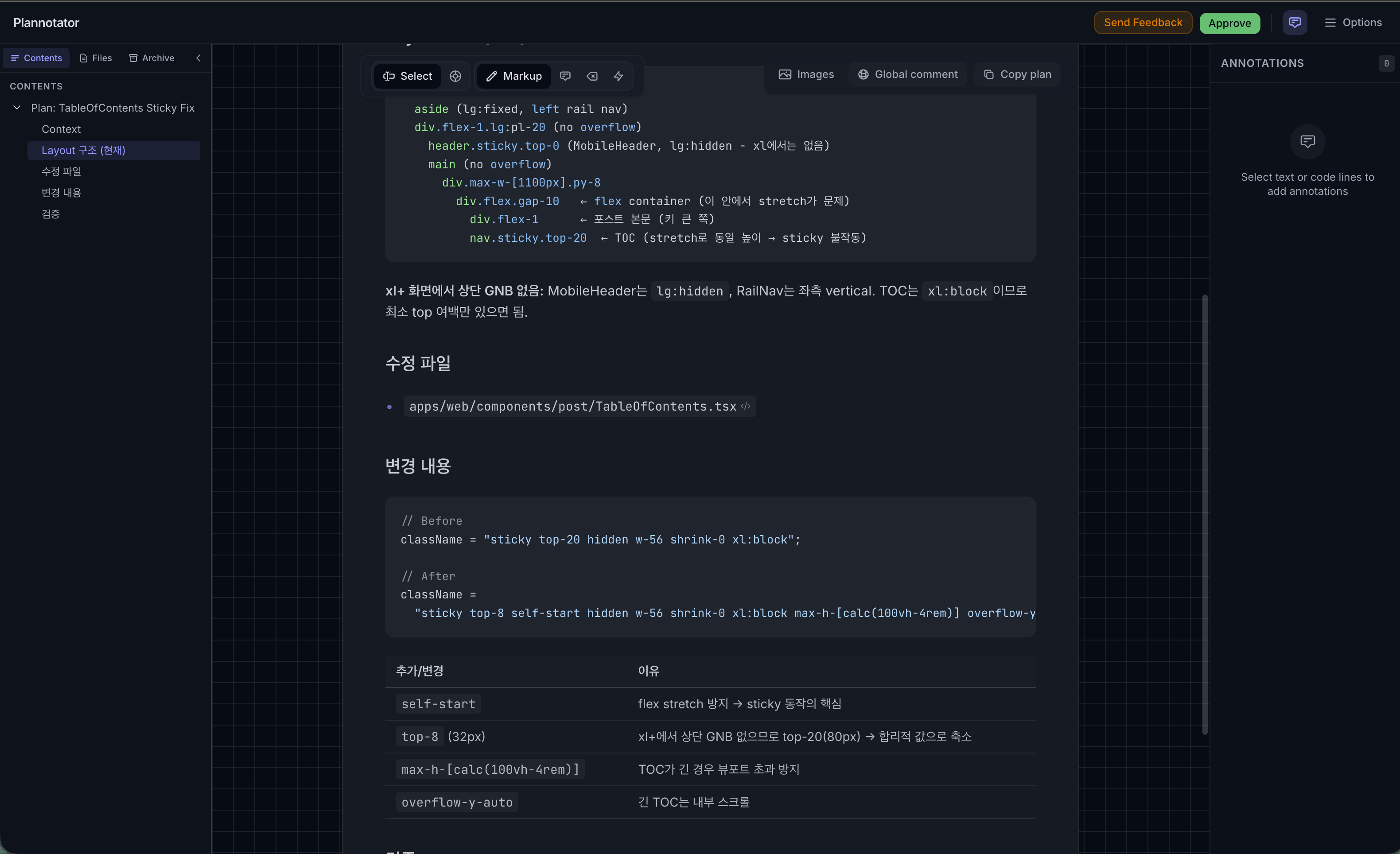
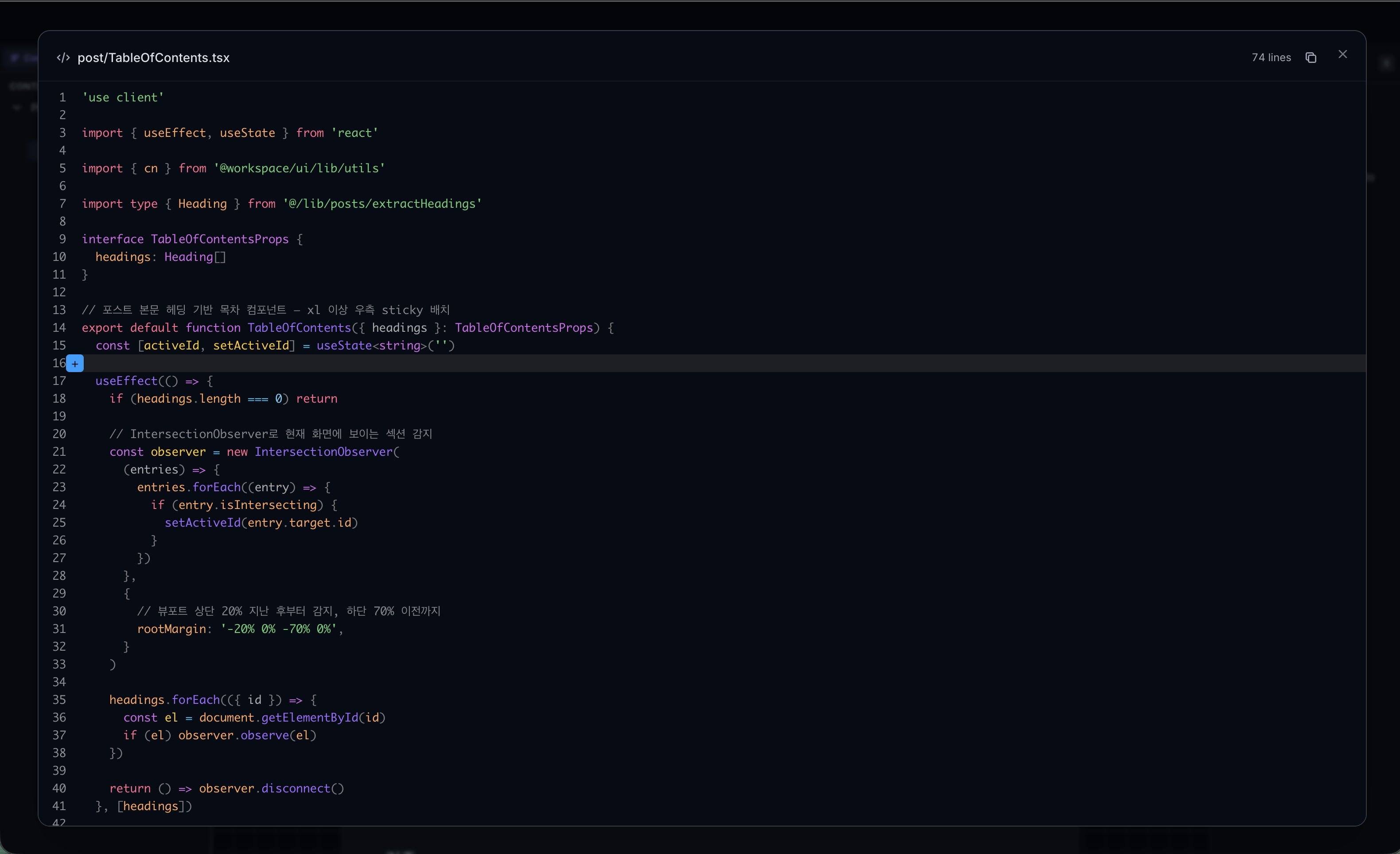
위 두 화면은 TableOfContents 컴포넌트의 sticky 레이아웃 계획을 점검하는 장면입니다. 계획만 보면 맞는 것 같아도, 실제 코드와 비교하면 놓친 부분이 보이는 경우가 많습니다. 항상 코드 구현 전에 plan을 수행하고, 이렇게 plannotator로 확인하면서 설계 일관성과 방향을 잃지 않을 수 있었습니다.
4. gstack skill 활용 — 코드 품질 개선 플랜 자동화
gstack skill은 AI Agent 개발 보조 스킬입니다.
QA 테스트, 성능 측정, 코드 리뷰 등 개발 사이클 전반을 지원하는 스킬 모음을 제공하는데요, 그 중 /review는 코드베이스를 "편집증적 스태프 엔지니어" 관점으로 분석합니다.
테스트를 통과했더라도 프로덕션에서 문제가 될 수 있는 지점 — N+1 쿼리, 레이스 컨디션, 보안 경계, 누락된 예외 처리 등을 탐지합니다. 명백한 결함은 자동으로 수정하고, 설계나 보안 판단이 필요한 항목은 [FLAGGED]로 분류해 사람이 검토하도록 넘깁니다. 플랜 모드로 실행 시 Plannotator에서 실제 코드와 나란히 열립니다.
기능을 빠르게 구현하고 덧붙여 가다보면 "현재 작업한 코드가 얼마나 안전한가"를 놓치기 쉽습니다.
1인 개발임을 감안하여, 주요 기능이 어느 정도 갖춰진 시점에 /review를 돌려서 개선 포인트를 한 번씩 정리했습니다.
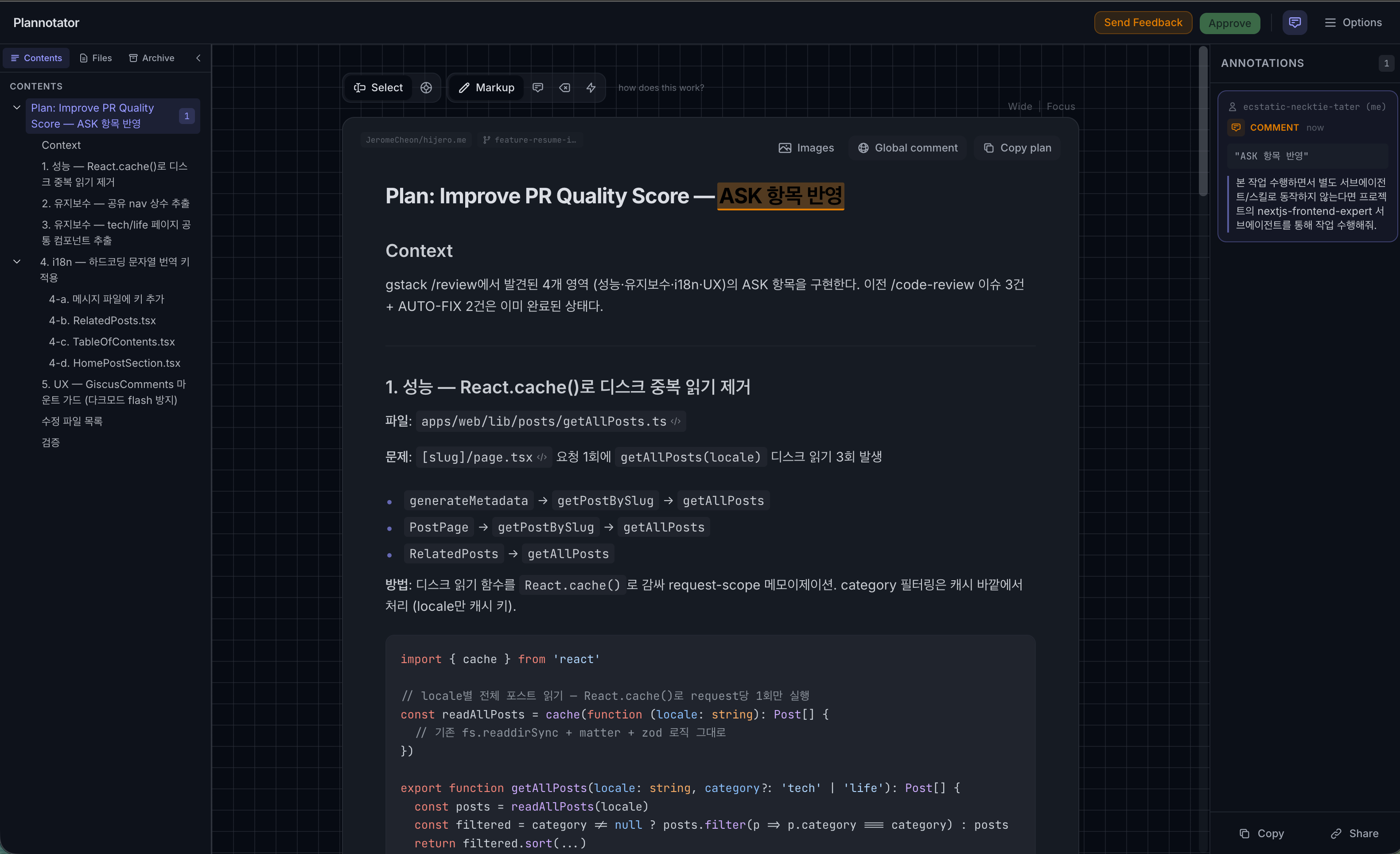
위 화면은 getAllPosts.ts에서 React.cache() 중복 호출을 제거하는 최적화 플랜을 Plannotator로 확인하는 모습입니다.
문제 지점, 수정 방향, 대상 코드까지 한 화면에서 파악할 수 있어 리뷰 루프가 크게 단축됐습니다.
도구들의 실제 모습을 살펴봤으니, 이제 이 흐름 위에서 구현된 핵심 기능들을 차례로 살펴보겠습니다.
i18n: Next.js App Router에서의 다국어 처리
전 회사에서의 다국어 기능 구현 경험을 되살려, 이 웹 서비스에도 다국어 지원 기능을 추가하면 좋겠다는 생각이 들었습니다.
LinkedIn으로나 웹 서칭을 통해 해외 개발자들과도 소통할 일이 생길 수 있고 이 사이트가 그 접점이 되길 바라는 것도 있어 처음부터 라우팅 구조를 다국어 친화적으로 잡고 시작했습니다.
next-intl 라이브러리를 사용해 Next.js 16 App Router 환경에 맞게 [locale] 동적 라우팅을 구성했고, 우선은 한국어(ko)와 영어(en) 두 언어를 지원하도록 구성했습니다.
설계 시 고려하고 알맞게 반영한 사항은 다음과 같습니다.
- 미들웨어 기반 자동 언어 감지: 접속자의 브라우저 언어(Accept-Language)를 감지해 자동으로 적합한 언어 페이지로 리다이렉트되도록 설정
- 경로 유지 토글: 우상단 Pinned GNB에 있는 언어 토글 버튼을 누르면 현재 읽고 있는 페이지의 경로를 그대로 유지한 채 언어만
ko↔en으로 전환되도록useRouter와usePathname을 활용
모던하고 유연한 내비게이션 (Rail & Sheet)
레이아웃은 데스크탑과 모바일 환경을 모두 만족시키기 위해 반응형 2-column 그리드로 설계했습니다.
디자인 레퍼런스로 삼은 UntitledUI 포트폴리오 디자인을 분석하면서 어떻게 구현해야 할지 초안을 잡는 데 큰 도움이 됐습니다. 아래 스크린샷처럼 상단 헤더 대신 화면 좌측에 아이콘+레이블로 구성된 Rail Navigation을 두고, 중앙은 배너-아바타 헤더와 콘텐츠 피드로 채우는 구도입니다. 콘텐츠 면적을 최대화하면서도 내비게이션 접근성을 유지할 수 있는 레이아웃이라고 생각하여 base로 삼았습니다.
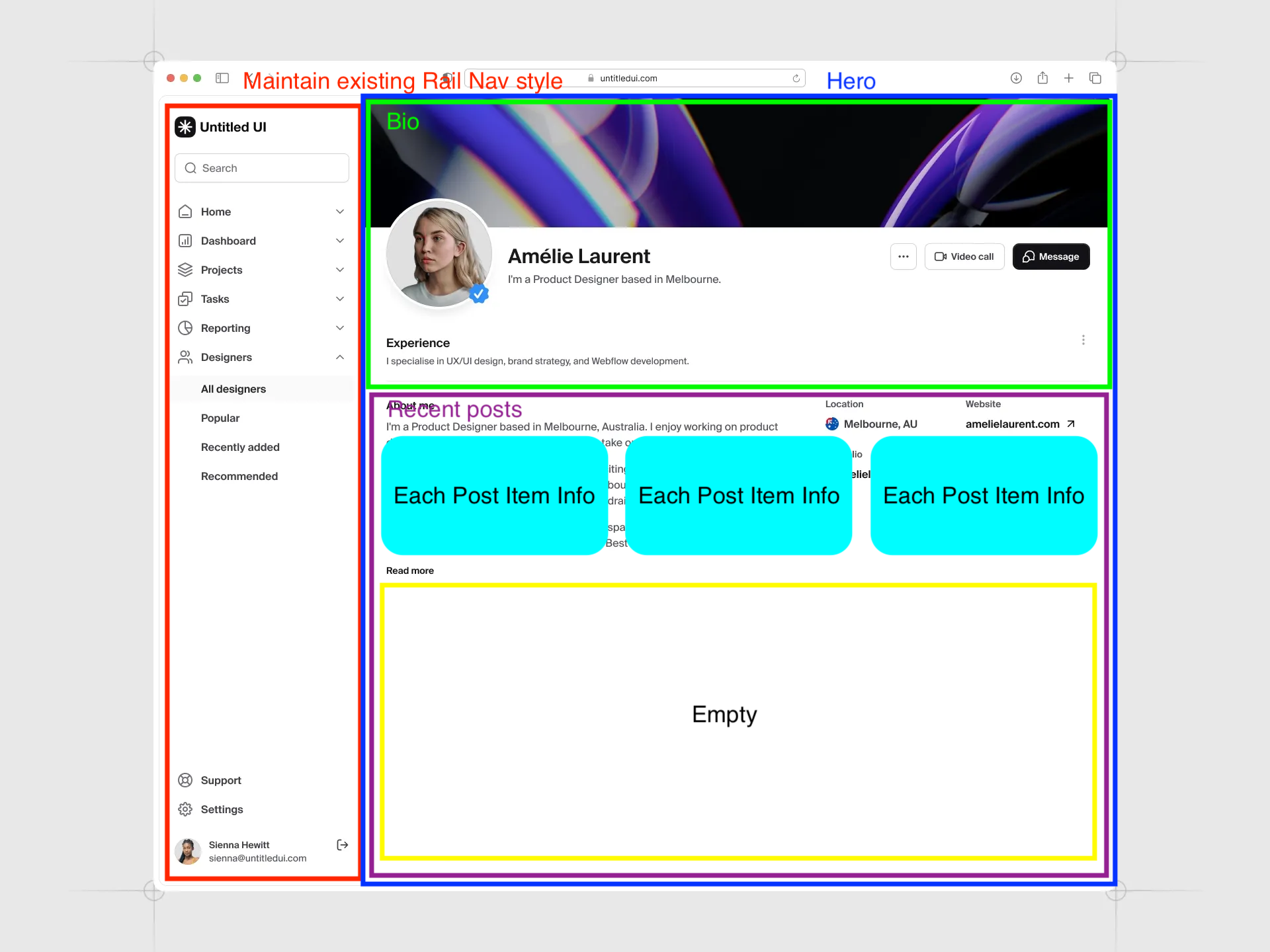
- 데스크탑 (Rail Navigation): Material Design 3의 Rail 패턴을 채택. 화면 좌측에 80px 너비로 고정되어 넓은 화면을 효율적으로 사용하면서도, 각 메뉴에 아이콘과 레이블을 함께 배치해 직관성을 높임. 하단에는 소셜 링크와 프로필을 배치하고 CSS-only 툴팁으로 부드러운 상호작용을 더함.
- 모바일 (Header & Sheet): 모바일 환경에서는 Rail을 숨기고 상단 고정 헤더와 햄버거 메뉴를 둠. 메뉴를 누르면
shadcn/ui의 Sheet 컴포넌트가 슬라이드되며 등장하도록 해 일관된 메뉴 접근 경험을 제공함.
MDX 콘텐츠 파이프라인 구축
블로그 포스트는 별도의 CMS나 데이터베이스를 사용하지 않고 개발자 친화적인 MDX(Markdown + JSX) 파일 형식으로 설계했습니다.
- 파서 및 하이라이터:
gray-matter로 포스트의 메타데이터(frontmatter)를 파싱하고,Zod스키마로 타입을 엄격히 검증. 코드 블록은rehype-pretty-code와shiki를 결합해 다크/라이트 모드 테마 전환에 맞게 자연스럽게 변경되도록 구성. - 정적 생성(SSG):
generateStaticParams를 통해 빌드 시점에 모든 포스트를 정적 생성.
frontmatter를 검증하는 Zod 스키마는 다음과 같이 구성했습니다:
export const frontmatterSchema = z.object({
slug: z.string().min(1),
title: z.string().min(1),
description: z.string().min(1),
category: z.enum(['tech', 'life']),
tags: z.array(z.string()).default([]),
publishedAt: z
.string()
.regex(/^\d{4}-\d{2}-\d{2}/, 'YYYY-MM-DD 형식이어야 합니다'),
featured: z.boolean().optional(),
series: z
.object({ title: z.string(), slug: z.string(), order: z.number() })
.optional(),
})타입 검증을 빌드 타임에 강제하여, 날짜 포맷 오류나 잘못된 카테고리 값으로 인한 런타임 버그를 방지하였습니다.
디테일을 살린 포스트 UX
단순히 글을 보여주는 것에 그치지 않고, 읽는 사용자 경험 자체를 편안하게 만들어줄 여러 장치들을 다음과 같이 고안해 보았습니다.
1. 자동화된 목차 (Table of Contents)
rehype-slug로 헤딩 태그에 ID를 부여하고, IntersectionObserver로 스크롤 위치에 따라 현재 읽고 있는 섹션을 강조합니다.
const observer = new IntersectionObserver(
(entries) => {
entries.forEach((entry) => {
if (entry.isIntersecting) setActiveId(entry.target.id)
})
},
{
// 뷰포트 상단 20% 지난 후, 하단 70% 이전까지만 감지
rootMargin: '-20% 0% -70% 0%',
}
)rootMargin: '-20% 0% -70% 0%'가 핵심입니다.
기본 설정(0px)을 쓰면 헤딩이 화면에 살짝 보이는 순간 TOC가 전환되어 너무 민감하게 반응하는데요,
이 값으로 뷰포트의 "중간 10% 구간"에 들어왔을 때만 활성화되도록 좁혀주면 스크롤할 때 현재 읽고 있는 섹션이 자연스럽게 강조됩니다.
2. 읽기 진행률 바 & 예상 읽기 시간
상단에 얇은 라인으로 스크롤 진행도를 표시하는 진행률 바와, 포스트 헤더에 보이는 예상 읽기 시간은 독자가 지금 얼마나 읽었고 얼마나 남았는가 를 직관적으로 파악하게 합니다.
진행률 바는 스크롤 이벤트마다 DOM을 직접 계산하는 대신, requestAnimationFrame으로 프레임 단위 일괄 처리를 합니다.
이미 예약된 rAF가 있으면 핸들러를 건너뛰어 중복 계산을 방지합니다.
const handleScroll = () => {
if (rafId !== null) return // 이미 rAF 예약됨 → 스킵
rafId = requestAnimationFrame(() => {
const total = document.documentElement.scrollHeight - window.innerHeight
setProgress(total > 0 ? (window.scrollY / total) * 100 : 0)
rafId = null
})
}
window.addEventListener('scroll', handleScroll, { passive: true })passive: true를 붙이면 브라우저가 이 리스너가 preventDefault()를 호출하지 않는다고 확신하고, 스크롤 렌더링 파이프라인을 차단하지 않습니다.
한편, 예상 읽기 시간은 reading-time 패키지로 산출합니다.
const stats = readingTime(content)
const readingTimeMin = Math.ceil(stats.minutes)산출 메커니즘: 유니코드 범위로 CJK 문자(한글: U+AC00–U+D7A3)를 감지하고, 각 CJK 문자를 독립된 1단어로 계산합니다.
영문과 동일하게 분당 200단어(WPM) 기준을 적용합니다.
정확도와 실효성: 실제 한국어 성인 평균 읽기 속도는 약 400–500 CPM(분당 글자 수)인데, 이 라이브러리는 200 글자/분으로 계산하므로 한국어 포스트는 실제보다 약 2–2.5배 길게 추정되는 경향이 있습니다. 영어는 200 WPM이 평균에 근접해 비교적 정확합니다.
개인 블로그 맥락에서는 이 특성이 크게 문제되지 않습니다. "예상 시간보다 빨리 다 읽었다"는 경험은 독자에게 긍정적으로 작용하고, 보수적 추정이 체류 시간을 낮게 잡는 것보다 낫기 때문입니다. 표시 형식은 로케일에 맞게 분리됩니다.
- 한국어: "5분 소요"
- 영어: "Read 5 min"
3. 태그 기반 관련 포스트 추천
현재 글과 태그 교집합이 있는 포스트들을 계산해 글 하단에 최대 3개까지 노출시켜 글을 다 읽은 사용자의 서비스 체류 시간을 늘릴 수 있도록 했습니다. "태그가 겹치면 보여주는" 단순 필터가 아니라, 많이 겹칠수록 상위에 오도록 다음과 같이 점수를 매겼습니다.
function scorePost(current: Post, candidate: Post): number {
const intersection = candidate.tags.filter((t) => current.tags.includes(t))
return intersection.length
}
const related = allPosts
.filter((p) => p.slug !== currentPost.slug)
.map((p) => ({ post: p, score: scorePost(currentPost, p) }))
.filter(({ score }) => score > 0)
.sort((a, b) =>
b.score !== a.score
? b.score - a.score
: new Date(b.post.publishedAt).getTime() -
new Date(a.post.publishedAt).getTime()
)
.slice(0, 3)
.map(({ post }) => post)태그 겹침 수가 같은 경우에는 최신 포스트를 우선합니다. getAllPosts(locale)로 현재 언어의 포스트만 불러오기 때문에, 한국어 포스트에서는 한국어 관련 글만, 영어 포스트에서는 영어 관련 글만 추천됩니다.
백엔드 로직: 쿠키 없는 깔끔한 조회수 측정 (Server Actions + Supabase)
포스트가 등록된 시점 부터 조회수가 얼마나 되는지 디스플레이 하는 기능도 있으면 좋겠다고 생각했습니다. 이때, 방문자들의 개인정보를 수집하거나 쿠키를 사용하지 않고 조회수를 측정하기 위한 방법에 대해 고민을 좀 했습니다.
먼저 조회수를 저장하기 위한 데이터베이스 구축과 백엔드 로직은 Supabase를 선택함으로써 해결했습니다.
데이터베이스는 Supabase가 채택하고 있는 PostgreSQL의 기능을 활용하여 구축하고, Next.js의 서버 액션(Server Actions)을 사용해 조회수를 관리했습니다.
구성한 데이터베이스 구조는 두 테이블로 나뉩니다. post_views는 포스트별 누적 조회수를, post_view_logs는 24시간 중복 차단을 위한 뷰어 기록을 담습니다.
-- 포스트별 누적 조회수
create table post_views (
slug text primary key,
view_count integer default 0,
updated_at timestamptz default now()
);
-- 24시간 중복 방지용 뷰어 로그
create table post_view_logs (
id uuid primary key default gen_random_uuid(),
slug text not null,
viewer_fingerprint text not null,
viewed_at timestamptz default now()
);중복 체크와 카운트 증가를 한 번에 처리하는 로직은 Supabase RPC 함수(increment_post_view)로 분리했습니다.
애플리케이션 레이어에서 두 번의 쿼리를 보내는 대신, DB 측에서 트랜잭션을 보장하도록 하기 위해서입니다.
"개인정보를 수집하거나 쿠키를 쓰지 않으면서도 중복 조회를 방지하는 것" 에 대한 고민을 한 끝에 서버 액션에서 요청 헤더의 IP, User-Agent, Accept-Language를 조합해 SHA-256 해시로 Viewer Fingerprint를 생성하는 방식을 택했습니다.
async function buildFingerprint(
ip: string,
ua: string,
lang: string
): Promise<string> {
const raw = `${ip}|${ua}|${lang}`
const encoded = new TextEncoder().encode(raw)
const hashBuffer = await crypto.subtle.digest('SHA-256', encoded)
return Array.from(new Uint8Array(hashBuffer))
.map((b) => b.toString(16).padStart(2, '0'))
.join('')
}Web Crypto API(crypto.subtle)를 서버 사이드에서 직접 사용합니다.
Node.js 20+와 Edge Runtime 모두에서 추가 패키지 없이 동작한다는 점이 깔끔했습니다.
Supabase RPC 함수를 호출해 이 해시값을 기준으로 24시간 내 같은 글을 본 적이 있다면 카운트를 올리지 않도록 트랜잭션을 구성했고, 사용자 브라우저에 쿠키를 남기지 않으면서도 꽤 신뢰도 높은 조회수 측정이 가능해졌습니다.
글을 마무리하며
이렇게 AI 협업 도구에 대한 소개부터 i18n, MDX 파이프라인, 포스트 UX, 조회수 시스템 구축까지 살펴보았습니다.
이번 포스트를 쓰면서 돌이켜보니, 기능 하나하나를 구현하던 과정에서 가장 인상 깊었던 건 도구들이 단순히 코드를 대신 써주는 것 이상이었다는 점입니다. Shrimp Task Manager가 작업 순서를 정리해주고, 서브에이전트와 output-style을 결합하여 설계 결정에 주도적으로 참여한다는 것은 "개발한다"는 감각을 온전히 유지하면서도 빠르게 전진할 수 있는 균형점이었습니다.
다음 3편에서는 Notion을 CMS로 활용한 포트폴리오 관리, 서버 없이 동작하는 Command Palette 검색, 그리고 Vercel 배포와 SEO 설정까지 마무리 여정을 이야기해 보겠습니다.